Presenting multiple equivalent experiments: pool data or not?
June 10, 2009 10:13 AM
Experiment statistics & data representation: I need advice on presenting the difference between two experimental configurations. Should I pool the data from equivalent experiments or not?
I'd like to show the effect of changing an experimental condition, and I'm getting hung up on how best to express the average, sample number, standard error, etc.
The key quantity is the percentage of cells available over time from a syringe containing a cell suspension. The difference between the two experiments is whether the syringe is rotated or not rotated. (The cells sink and clump over time, and rotation keeps them suspended.)
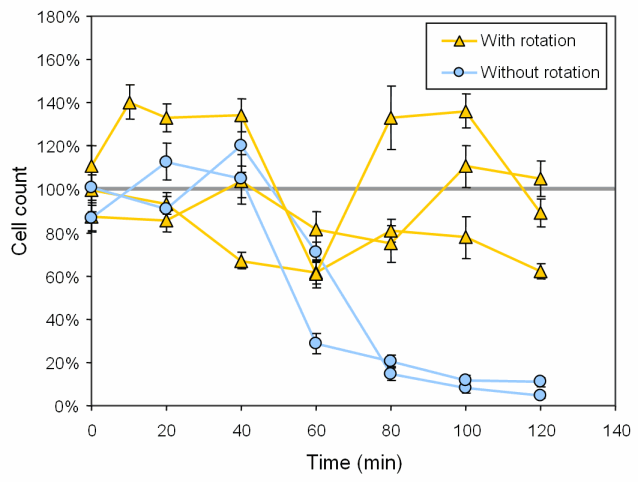
The current presentation is here. Every twenty minutes, a sample is taken from the syringe and the cells suspended in the sample are counted on n 1mm x 1mm cytometer squares, yielding n count values. The standard error is calculated as the standard deviation divided by sqrt(n). The average count and error are normalized to the average from the suspension before the syringe was loaded.
For example, typical cell density data might be:
Original suspension: 10,11,9,10,10 (average 10.0)
20-minute timepoint: 6,12,13,11,12 (average +/- SE 10.8+/-1.2)
So the 20-minute data point would be plotted at 108+/-12%. (Note that I've normalized the SE of this timepoint to the original suspension; this is one of the things I have a question about.)
I performed the experiment five times: three with rotation and two without. The cell density in the original suspension was different each time; thus, there's the need to normalize the counts and present the data as a percentage to show what I want to show.
A colleague asked if that data would be better presented by averaging all the with-rotation data together and all the without-rotation data together. I instinctively prefer my current presentation because it shows the viewer what I saw during each of the three experiments; averaging somewhat occludes this information.
So I ask the AskMefi statistics experts:
1. What is the best practice for presenting this data? Does it make sense to plot the experiments separately with SE calculated from the n cytometer measurements, or should the averages be pooled and the standard error calculated from the m separate experiments (3 and 2, respectively)? (Or is another approach preferable?)
2. If I take the revised approach, should I just take the total cytometer counts (50 and 54, for example, from the above sample data) and discard intra-cytometer variance? Is this lost information important?
3. If I stay with the current approach, what is the proper way to incorporate the variance of the baseline measurement (the cell count before the syringe is loaded) to properly present the standard error of a normalized value? (My hunch is to use error propagation techniques to pool the variance.)
Thank you!
I'd like to show the effect of changing an experimental condition, and I'm getting hung up on how best to express the average, sample number, standard error, etc.
The key quantity is the percentage of cells available over time from a syringe containing a cell suspension. The difference between the two experiments is whether the syringe is rotated or not rotated. (The cells sink and clump over time, and rotation keeps them suspended.)
The current presentation is here. Every twenty minutes, a sample is taken from the syringe and the cells suspended in the sample are counted on n 1mm x 1mm cytometer squares, yielding n count values. The standard error is calculated as the standard deviation divided by sqrt(n). The average count and error are normalized to the average from the suspension before the syringe was loaded.
{kind=link}
For example, typical cell density data might be:
Original suspension: 10,11,9,10,10 (average 10.0)
20-minute timepoint: 6,12,13,11,12 (average +/- SE 10.8+/-1.2)
So the 20-minute data point would be plotted at 108+/-12%. (Note that I've normalized the SE of this timepoint to the original suspension; this is one of the things I have a question about.)
I performed the experiment five times: three with rotation and two without. The cell density in the original suspension was different each time; thus, there's the need to normalize the counts and present the data as a percentage to show what I want to show.
A colleague asked if that data would be better presented by averaging all the with-rotation data together and all the without-rotation data together. I instinctively prefer my current presentation because it shows the viewer what I saw during each of the three experiments; averaging somewhat occludes this information.
So I ask the AskMefi statistics experts:
1. What is the best practice for presenting this data? Does it make sense to plot the experiments separately with SE calculated from the n cytometer measurements, or should the averages be pooled and the standard error calculated from the m separate experiments (3 and 2, respectively)? (Or is another approach preferable?)
2. If I take the revised approach, should I just take the total cytometer counts (50 and 54, for example, from the above sample data) and discard intra-cytometer variance? Is this lost information important?
3. If I stay with the current approach, what is the proper way to incorporate the variance of the baseline measurement (the cell count before the syringe is loaded) to properly present the standard error of a normalized value? (My hunch is to use error propagation techniques to pool the variance.)
Thank you!
FYI, the pooled version would look like this (mean +/- SE, m = 3 and 2).
posted by Mapes at 10:52 AM on June 10, 2009
.png){kind=link}
posted by Mapes at 10:52 AM on June 10, 2009
I like your existing approach since it basically tells what you have done. I prefer five curves with two colors over two curves, since anyone who wants to can average (by eye, at least) while un-averaging is impossible. Also with multiple curves an observer can decide that your error bars look reasonable.
I'm a little confused about your scaling. Shouldn't all the zero-minute data points be at 100% ?
posted by fantabulous timewaster at 11:17 AM on June 10, 2009
I'm a little confused about your scaling. Shouldn't all the zero-minute data points be at 100% ?
posted by fantabulous timewaster at 11:17 AM on June 10, 2009
How about using a box plot instead of s.e in the pooled version? That way, you can present more of the variance, as well as keeping the cleaner look of the pooled graph.
posted by dhruva at 11:41 AM on June 10, 2009
posted by dhruva at 11:41 AM on June 10, 2009
I'm a little confused about your scaling. Shouldn't all the zero-minute data points be at 100% ?
I should have mentioned: I also took a zero-minute sample immediately after loading the cells into the syringe.
posted by Mapes at 12:46 PM on June 10, 2009
I should have mentioned: I also took a zero-minute sample immediately after loading the cells into the syringe.
posted by Mapes at 12:46 PM on June 10, 2009
IAAS, and it's always nice to see the actual data. Might choose plotting symbols which distinguish the experiments a bit more or jitter the x-value a tiny amount so that you can see which error bars go to whom. Visually, I'm not a big fan of +-SEM if sample sizes are unequal (unless they are all very close).
The actual analysis should acknowledge three elements:
1) within-syringe sampling of cell counts (cytometer counts reflect something common to a syringe; the 8 from a single syringe a time t will be more like each other than like counts another syringe from the same population at time t)
2) within population sampling of syringes (syringes reflect something about treatments)
3) longitudinal dependence within a syringe (syringe as t+1 will be more like itself at t than another at t)
Crude pooling either between syringes or over time would be wrong. Your analysis should go in with a question, something like "is the change in cell count for pop A greater than for pop B at t=120?" Because the time-relationship and dependence are hard to specify, it's probably best to make a second plot. On the x-axis is time, on the y-axis are confidence intervals of change from baseline for the two groups. If you think that that over the first 20-40 minutes you functionally measured the same thing 2-3 times, you can write down the pooled estimate of baseline using those.
posted by a robot made out of meat at 1:11 PM on June 10, 2009
The actual analysis should acknowledge three elements:
1) within-syringe sampling of cell counts (cytometer counts reflect something common to a syringe; the 8 from a single syringe a time t will be more like each other than like counts another syringe from the same population at time t)
2) within population sampling of syringes (syringes reflect something about treatments)
3) longitudinal dependence within a syringe (syringe as t+1 will be more like itself at t than another at t)
Crude pooling either between syringes or over time would be wrong. Your analysis should go in with a question, something like "is the change in cell count for pop A greater than for pop B at t=120?" Because the time-relationship and dependence are hard to specify, it's probably best to make a second plot. On the x-axis is time, on the y-axis are confidence intervals of change from baseline for the two groups. If you think that that over the first 20-40 minutes you functionally measured the same thing 2-3 times, you can write down the pooled estimate of baseline using those.
posted by a robot made out of meat at 1:11 PM on June 10, 2009
Oh, okay. Then your zero-minute points should cluster within one or two standard errors of 100%, which they do.
In that case the relative (percent) uncertainties of each measurement and the baseline add in quadrature. So in your example, with baseline 10.00±0.31 and datum 10.80±1.24, the scaled data point is (10.8/10.0) = 1.08 and its uncertainty is 1.08 × √( (0.31/10.0)2 + (1.24/10.8)2 ) = 0.128. On your plot you would draw 108% ± 13%.
posted by fantabulous timewaster at 1:16 PM on June 10, 2009
In that case the relative (percent) uncertainties of each measurement and the baseline add in quadrature. So in your example, with baseline 10.00±0.31 and datum 10.80±1.24, the scaled data point is (10.8/10.0) = 1.08 and its uncertainty is 1.08 × √( (0.31/10.0)2 + (1.24/10.8)2 ) = 0.128. On your plot you would draw 108% ± 13%.
posted by fantabulous timewaster at 1:16 PM on June 10, 2009
Depends on the audience. I like the second one better, since it conveys your point in with the least ink.
posted by shothotbot at 1:19 PM on June 10, 2009
posted by shothotbot at 1:19 PM on June 10, 2009
This thread is closed to new comments.
I believe this data would be most useful as a graph with the two conditions as well as confidence intervals or SE plotted for each time point.
posted by parudox at 10:39 AM on June 10, 2009